
Python机器学习——随机森林
随机森林
随机森林(Random Forest)算法是一种集成学习算法,它通过构建多棵决策树并将它们的预测结果进行整合来提高模型的预测准确性和泛化能力。随机森林算法的核心思想是“集思广益”,即通过组合多个模型的预测来减少单一模型可能存在的偏差和方差,从而提高整体模型的性能。
单个决策树对训练数据往往具有较好的分类效果,但是对于未知新样本分类效果较差。为了提升模型对未知样本的分类效果,所以将多个简单的决策树组合起来,形成泛化能力更强的模型——随机森林。
具体操作
1 | !pip install --upgrade pandas |
读入训练集表格
1 | import pandas as pd |
1 | 表头信息: ['user_id', 'area_code', 'age', 'gender_id', 'join_date', 'zfk_type', 'user_type', 'group_type', 'jt_5gzd_flag', 'jt_5gwl_flag', 'change_equip_period_avg', 'term_brand', 'term_price', 'ztc_gprs_res', 'ztc_price', 'avg3_llb_flag', 'sl_flag', 'sl_type', 'avg3_tc_ll', 'avg3_tw_ll', 'avg3_dou', 'avg3_mou', 'avg3_llct_cnt', 'avg3_yyct_cnt', 'avg3_ll_bhd', 'avg3_sl_ll', 'll_bhd', 'sl_ll2', 'avg3_tc_price', 'avg3_tot_fee', 'avg3_ctll_fee', 'avg3_ctyy_fee', 'avg3_video_app1_cnt', 'avg3_video_app2_cnt', 'avg3_video_app_ll', 'avg3_music_app1_cnt', 'avg3_music_app2_cnt', 'avg3_music_app_ll', 'avg3_game_app1_cnt', 'avg3_game_app2_cnt', 'avg3_game_app_ll', 'sample_flag'] |
统计数据类型及缺失情况
1 | # 1. 检查数据类型和缺失值 |
1 | 数据类型: |
对训练集和预测集同时进行数据预处理
1 | import pandas as pd |
检测预处理情况
1 | # 文件路径 |
绘制关系曲线
1 | import pandas as pd |
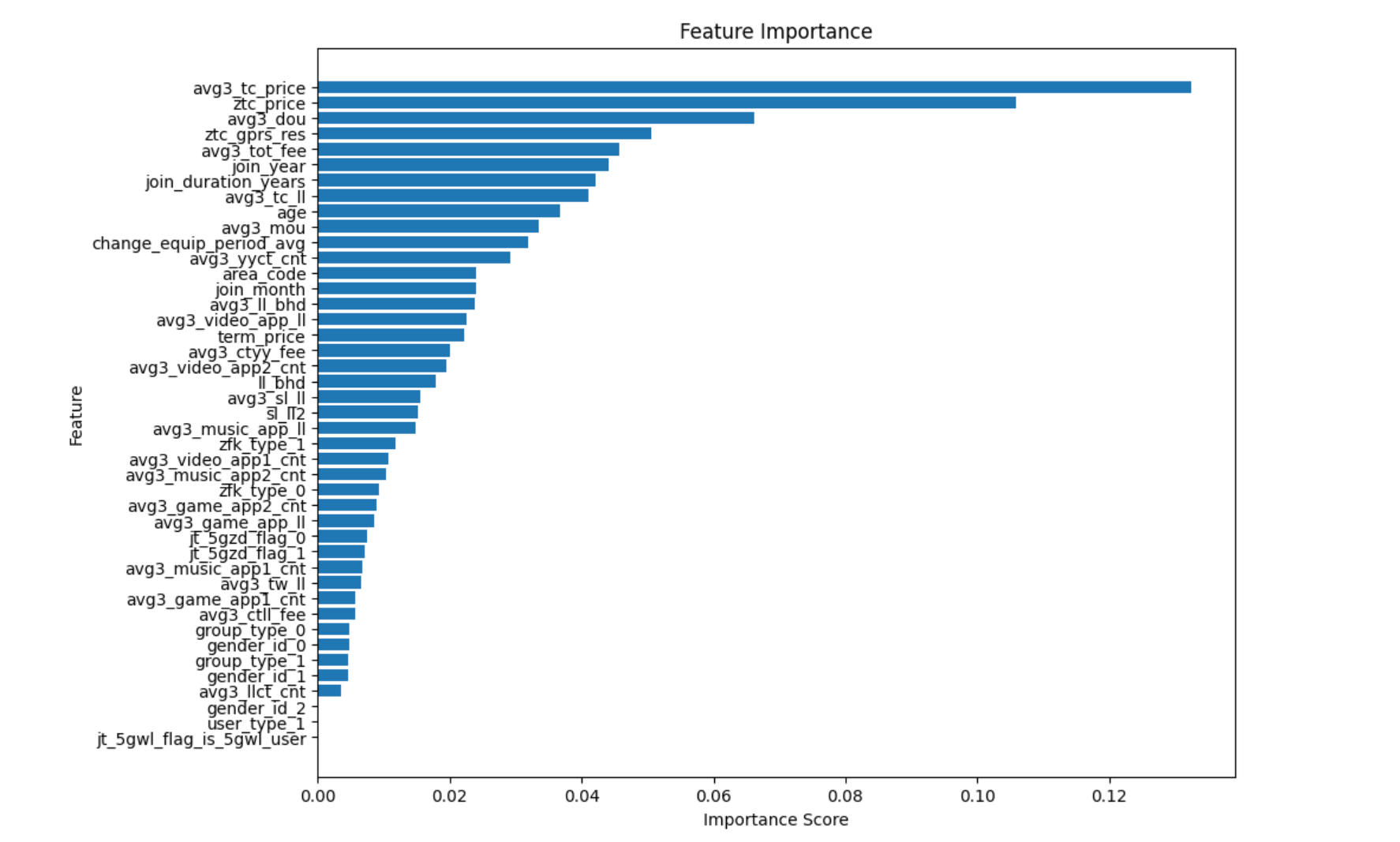
数据集划分(基于前十个重要特征进行训练)
将数据集分为训练集和测试集,确保模型能够在未见过的数据上进行评估。
控制基评估器的参数
| 参数 | 含义 |
|---|---|
| criterion | 不纯度的衡量指标(基尼系数和信息熵) |
| n_estimators | 树的数量 |
| max_depth | 树的最大深度,超过最大深度的树枝都会被剪掉 |
| min_samples_leaf | 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生 |
| min_samples_split | 一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生 |
| max_features | max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃,默认值为总特征个数开平方取整 |
| min_impurity_decrease | 限制信息增益的大小,信息增益小于设定数值的分枝不会发生 |
1 | import pandas as pd |
绘制学习
学习曲线可以展示模型在训练集和验证集上的表现,帮助判断是否存在过拟合或欠拟合的情况。
1 | from sklearn.model_selection import learning_curve |
过拟合
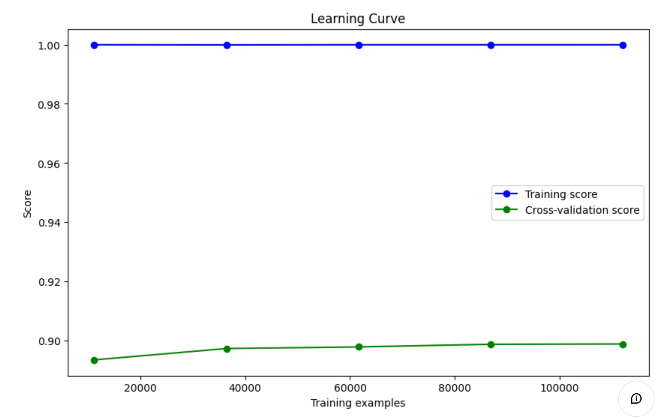
- 训练集表现:
- 蓝色曲线表示模型在训练集上的表现,接近于 1.0(即接近完美的得分),这表明模型在训练集上拟合得非常好。
- 这种情况通常说明模型在训练集上几乎没有误差,可能存在过拟合现象。
- 验证集表现:
- 绿色曲线表示模型在交叉验证集上的表现,得分较低,约在 0.90 左右,且随着训练数据量的增加,该分数并没有显著提升。
- 这种差距显示模型在验证集上表现不佳,表明模型可能过拟合训练数据,无法很好地泛化到未见的数据。
- 过拟合的迹象:
- 训练集和验证集的曲线差距较大,且训练集得分过高,这通常是过拟合的典型表现。
- 模型能够很好地记住训练集的数据,但在验证集上表现欠佳,说明模型可能过于复杂,未能有效学习到数据的泛化特征。
欠拟合
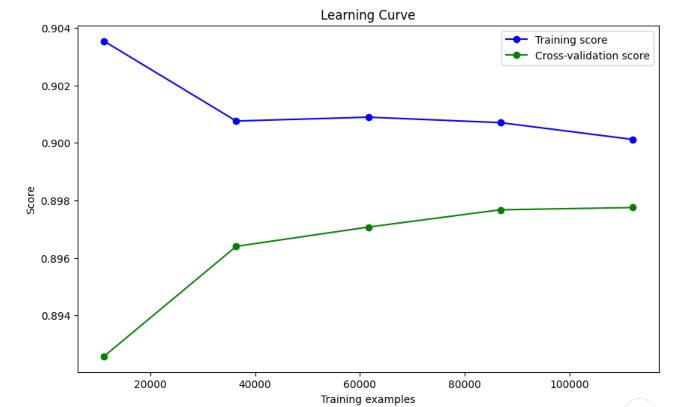
- 训练分数(蓝线)随着训练样本增加而下降,表明模型的复杂度下降,这是正常的现象。训练集上的分数稍高,意味着模型对训练集的拟合较好,但有逐步降低的趋势。
- 验证分数(绿线)随着训练样本的增加有所上升,并逐渐趋于稳定,表明模型在验证集上的表现正在提升。
尽管训练和验证曲线之间的差距不算太大,验证分数的表现并没有完全收敛到训练分数的水平。这可能是一个 轻微的欠拟合,但总体表现还可以。这表明模型的复杂度可能不足,或者特征还可以进一步优化。
参数调整对拟合情况的影响总结:
- n_estimators(树的数量):增加
n_estimators会提高模型的表现,因为更多的树可以捕捉更多的模式,但增至一定量后会趋于平稳且带来计算开销。200 棵树应该是合理的设置。 - max_depth(树的最大深度):限制树的深度(如设置为10)可以防止过拟合。如果深度太小,可能导致欠拟合(模型的表现有限)。增加
max_depth会提高模型复杂度,但也增加过拟合的风险。 - min_samples_split(节点划分的最小样本数):增大该参数(如设置为10)可以让模型要求更多数据点才能进一步分裂,这样减少了树的复杂度,进而减少过拟合风险。
- min_samples_leaf(叶节点的最小样本数):设置叶节点的最小样本数为5,可以确保模型不会为了少数样本创建过多的分支,避免过拟合。
- max_features(每次分裂时考虑的最大特征数):设置
max_features='sqrt'意味着在每次分裂时考虑一部分随机特征,这通常有助于降低过拟合。这个设置尤其适合高维特征的数据集。
绘制验证曲线
验证曲线可以显示超参数变化时的模型表现,从而帮助你进一步优化超参数。
1 | from sklearn.model_selection import validation_curve |

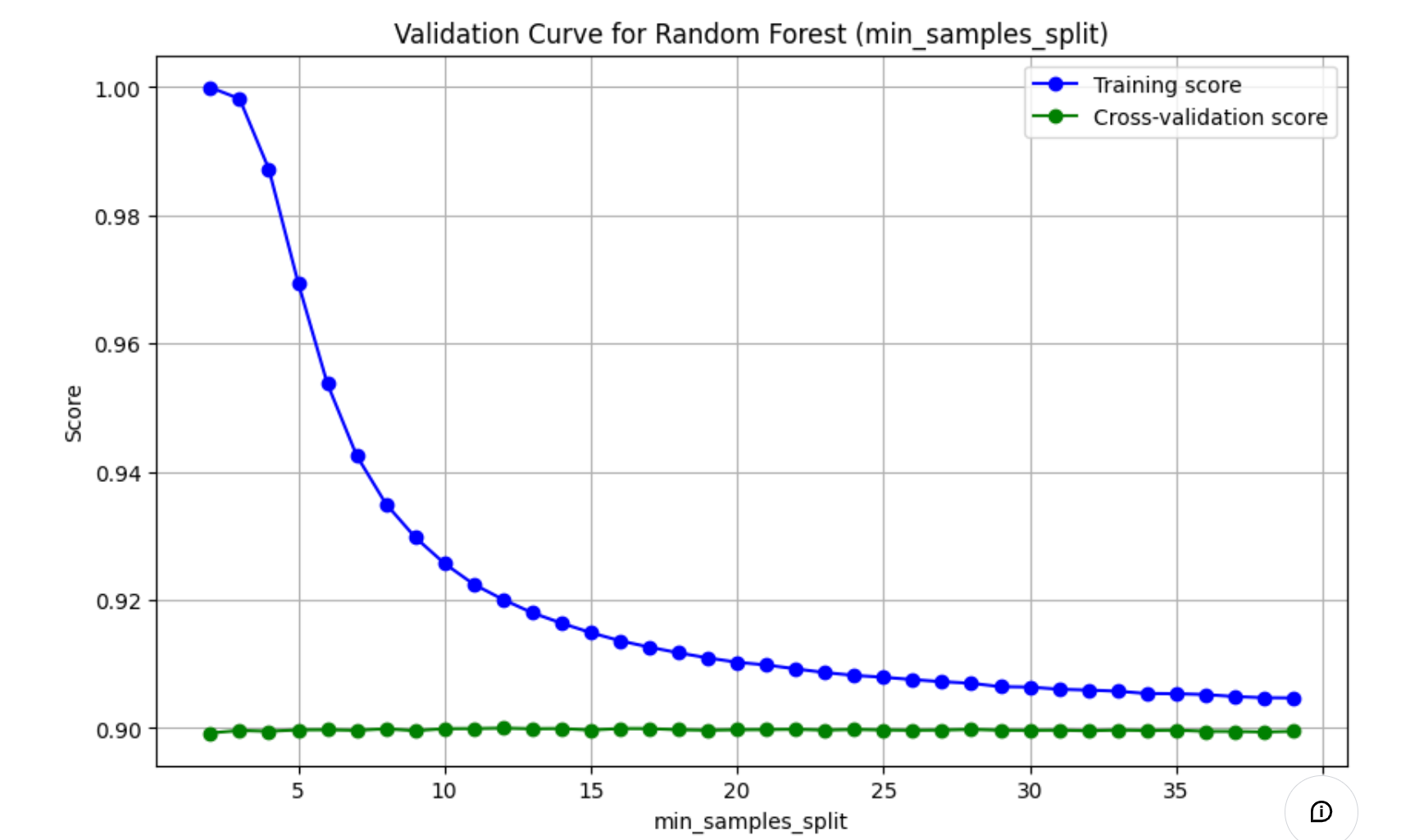
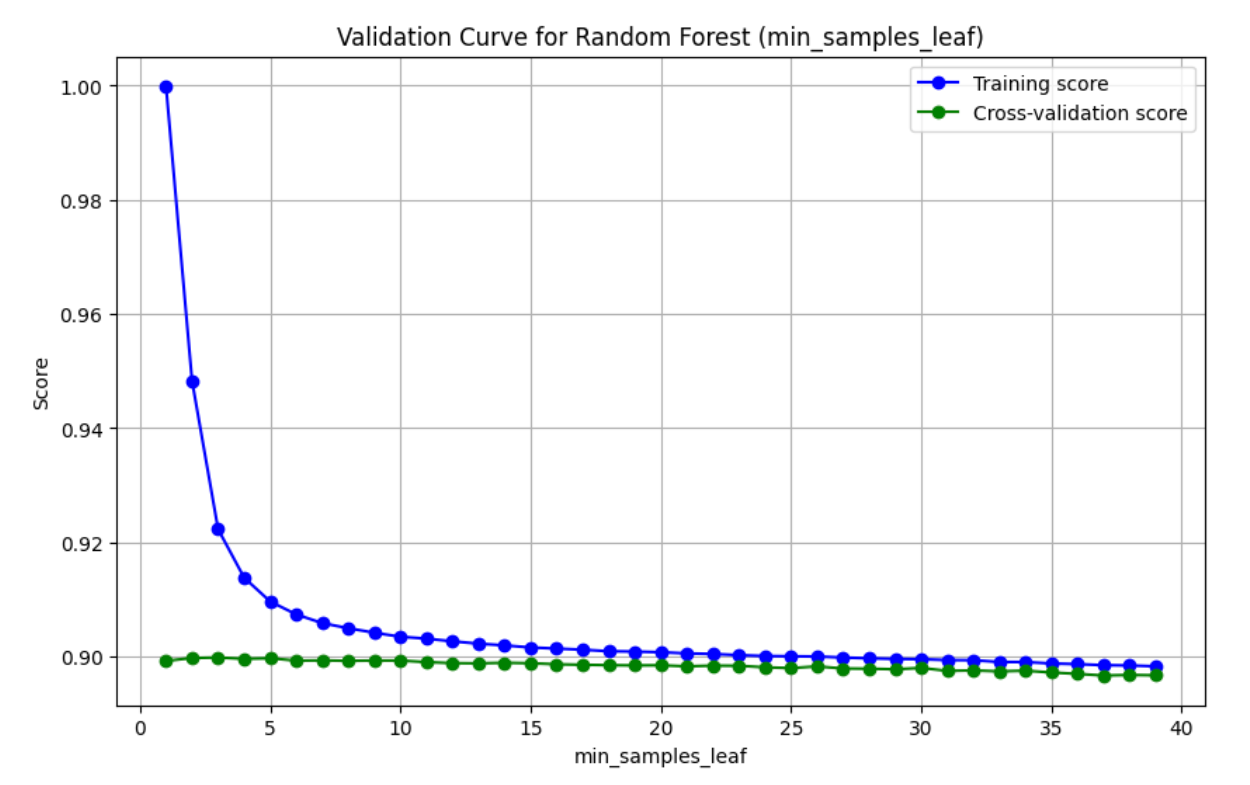
- 训练得分(Training score):表示模型在训练集上的准确率。随着
max_depth的增加,训练得分可能会先增加后减少,因为模型可能会逐渐适应训练数据,但最终可能会过拟合。 - 交叉验证得分(Cross-validation score):表示模型在交叉验证集上的准确率。这是一个更可靠的性能指标,因为它考虑了模型在未见过的数据上的表现。
- 曲线的形状:通常,随着
max_depth的增加,模型的复杂度增加,训练得分可能会提高,但交叉验证得分在达到某个点后可能会下降,这表明模型开始过拟合。 - 通过这个验证曲线,你可以找到最佳的
max_depth值,使得模型在训练集和验证集上都能达到较好的性能,从而避免过拟合。
参数选择
- 找到交叉验证得分最高的点:这是模型在未见过的数据上表现最好的点。
- 检查过拟合:如果训练得分和交叉验证得分之间的差距很大,这可能意味着过拟合。选择一个差距较小的点以避免过拟合。
- 考虑实际应用:在实际应用中,你可能需要考虑模型的复杂度和训练时间。较深的树可能需要更长的时间来训练。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 polar-bear~Blog!
 wechat
wechat Alipay
Alipay
评论



