D-FINE
D-FINE 是一个强大的实时目标检测器,将 DETR 中的边界框回归任务重新定义为了细粒度的分布优化(FDR),并引入全局最优的定位自蒸馏(GO-LSD),在不增加额外推理和训练成本的情况下,实现了卓越的性能。
Peterande/D-FINE: D-FINE: Redefine Regression Task of DETRs as Fine-grained Distribution Refinement [ICLR 2025 Spotlight]
数据集-OpenDataLab
D-FINE 论文理解_dfine-CSDN博客
D-FINE:实时目标检测的“速度与激情”,精准又高效! - 知乎
训练
数据集准备
准备数据集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 import json import random import xml.etree.ElementTree as ET from pathlib import Path IMG_EXTS = [".jpg", ".jpeg", ".png", ".bmp", ".webp"] # ========================== # Hardcoded runtime settings # ========================== SETTINGS = { "images_dir": "coco/images", "xml_dir": "coco/Annotations", "output_dir": "coco/converted", "train_ratio": 0.8, "val_ratio": 0.1, "test_ratio": 0.1, "seed": 42, } def parse_xml(xml_path: Path): root = ET.parse(xml_path).getroot() filename = (root.findtext("filename") or "").strip() size = root.find("size") if size is None: return None w = int(float(size.findtext("width", default="0"))) h = int(float(size.findtext("height", default="0"))) if w <= 0 or h <= 0: return None objs = [] for obj in root.findall("object"): name = (obj.findtext("name") or "").strip() box = obj.find("bndbox") if not name or box is None: continue xmin = float(box.findtext("xmin", default="0")) ymin = float(box.findtext("ymin", default="0")) xmax = float(box.findtext("xmax", default="0")) ymax = float(box.findtext("ymax", default="0")) if xmax <= xmin or ymax <= ymin: continue objs.append((name, xmin, ymin, xmax, ymax)) if not objs: return None return filename, w, h, objs def find_img(images_dir: Path, stem: str): for ext in IMG_EXTS: p = images_dir / f"{stem}{ext}" if p.exists(): return p return None def to_coco(samples, cls2id): images, annotations = [], [] ann_id = 1 for img_id, s in enumerate(samples, start=1): images.append({ "id": img_id, "file_name": s["file_name"], "width": s["width"], "height": s["height"], }) for cls_name, xmin, ymin, xmax, ymax in s["objects"]: w = xmax - xmin h = ymax - ymin annotations.append({ "id": ann_id, "image_id": img_id, "category_id": cls2id[cls_name], "bbox": [xmin, ymin, w, h], "area": w * h, "iscrowd": 0, }) ann_id += 1 categories = [ {"id": cid, "name": name, "supercategory": "object"} for name, cid in sorted(cls2id.items(), key=lambda x: x[1]) ] return {"images": images, "annotations": annotations, "categories": categories} def dump_json(path: Path, data): path.parent.mkdir(parents=True, exist_ok=True) path.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8") def dump_lines(path: Path, lines): path.parent.mkdir(parents=True, exist_ok=True) path.write_text("\n".join(lines) + "\n", encoding="utf-8") def main(): if abs(SETTINGS["train_ratio"] + SETTINGS["val_ratio"] + SETTINGS["test_ratio"] - 1.0) > 1e-6: raise ValueError("train/val/test ratio sum must be 1.0") images_dir = Path(SETTINGS["images_dir"]).resolve() xml_dir = Path(SETTINGS["xml_dir"]).resolve() out_dir = Path(SETTINGS["output_dir"]).resolve() xml_files = sorted([p for p in xml_dir.glob("*.xml") if not p.name.startswith(".")]) if not xml_files: raise FileNotFoundError(f"No xml files found in {xml_dir}") samples = [] cls_names = set() skipped = 0 for xp in xml_files: parsed = parse_xml(xp) if parsed is None: skipped += 1 continue filename, w, h, objs = parsed stem = Path(filename).stem if filename else xp.stem img_path = find_img(images_dir, stem) if img_path is None: skipped += 1 continue cls_names.update([o[0] for o in objs]) samples.append({ "file_name": img_path.name, "width": w, "height": h, "objects": objs, "abs_path": img_path.as_posix(), }) if not samples: raise RuntimeError("No valid samples generated") cls2id = {name: i for i, name in enumerate(sorted(cls_names))} random.Random(SETTINGS["seed"]).shuffle(samples) n = len(samples) n_train = int(n * SETTINGS["train_ratio"]) n_val = int(n * SETTINGS["val_ratio"]) train = samples[:n_train] val = samples[n_train:n_train + n_val] test = samples[n_train + n_val:] ann_dir = out_dir / "annotations" split_dir = out_dir / "splits" dump_json(ann_dir / "train.json", to_coco(train, cls2id)) dump_json(ann_dir / "val.json", to_coco(val, cls2id)) dump_json(ann_dir / "test.json", to_coco(test, cls2id)) dump_lines(split_dir / "train.txt", [x["abs_path"] for x in train]) dump_lines(split_dir / "val.txt", [x["abs_path"] for x in val]) dump_lines(split_dir / "test.txt", [x["abs_path"] for x in test]) ultralytics_yaml = out_dir / "ultralytics_data.yaml" ultralytics_yaml.write_text( "\n".join([ f"train: {(split_dir / 'train.txt').as_posix()}", f"val: {(split_dir / 'val.txt').as_posix()}", f"test: {(split_dir / 'test.txt').as_posix()}", f"nc: {len(cls2id)}", f"names: {[name for name, _ in sorted(cls2id.items(), key=lambda x: x[1])]}", ]) + "\n", encoding="utf-8", ) summary = { "images_total": n, "train": len(train), "val": len(val), "test": len(test), "classes": sorted(cls_names), "num_classes": len(cls_names), "skipped_files": skipped, "output_dir": out_dir.as_posix(), } dump_json(out_dir / "summary.json", summary) print(json.dumps(summary, ensure_ascii=False, indent=2)) if __name__ == "__main__": main()
创建自定义配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 # 单目标 volleyball 实验配置:S 模型 + Objects365 预训练迁移 # 用法(在 D-FINE 目录下执行): # python train.py -c ../config/volleyball_s_transfer.yml --use-amp --seed 0 -t weights/dfine_s_obj365.pth __include__: [ '../D-FINE/configs/dfine/custom/objects365/dfine_hgnetv2_s_obj2custom.yml', ] # 实验输出目录(相对 D-FINE 工作目录) output_dir: ./output/exp_s_transfer_obj_aug # 数据集设置:单类别,且不做 COCO80 类别重映射 num_classes: 1 remap_mscoco_category: False # ============ 数据增强配置 ============ # 启用更激进的数据增强来改进小数据集性能 train_dataloader: collate_fn: # 多尺度训练 base_size: 640 base_size_repeat: 10 stop_epoch: 56 ema_restart_decay: 0.9999 type: BatchImageCollateFunction dataset: img_folder: C:/Users/Rick/Desktop/python/ObjectDetection/coco/images ann_file: C:/Users/Rick/Desktop/python/ObjectDetection/coco/converted/annotations/train.json return_masks: False type: CocoDetection drop_last: True num_workers: 4 shuffle: True total_batch_size: 32 type: DataLoader val_dataloader: collate_fn: type: BatchImageCollateFunction dataset: img_folder: C:/Users/Rick/Desktop/python/ObjectDetection/coco/images ann_file: C:/Users/Rick/Desktop/python/ObjectDetection/coco/converted/annotations/val.json return_masks: False # 验证集使用最小增强 transforms: type: Compose ops: # 只进行必需的变换,不做随机增强 - type: Resize size: [640, 640] - type: ConvertPILImage dtype: float32 scale: True - type: ConvertBoxes fmt: cxcywh normalize: True type: CocoDetection drop_last: False num_workers: 4 shuffle: False total_batch_size: 64 type: DataLoader # 每 N 轮额外保存一次 checkpointxxxx.pth(last/best 仍会按训练逻辑保存) checkpoint_freq: 6 # 从12改为6,保存更频繁 # 训练总轮次 epochs: 160 # 从120增加到160,更长的训练 # ========== 额外优化参数 ========== # 学习率预热 lr_warmup_scheduler: type: LinearWarmup warmup_duration: 500 # 预热500步 # EMA模型平滑 ema: type: ModelEMA decay: 0.9999 start: 0 warmups: 2000 # 梯度裁减 clip_max_norm: 0.1 # 同步批归一化(多卡训练) sync_bn: True
训练
参考51hhh/D-FINE_train: D-FINE 自定义配置训练
-r (resume) 和 -t (tuning)
-r (resume)
恢复全部状态:模型权重 + 优化器 + last_epoch + lr_scheduler
-t (tuning)
只加载模型权重,epoch 从 0 开始,优化器全新
-r (resume)
-t (tuning)
模型权重
加载
加载
优化器状态
恢复
全新
last_epoch
恢复 (=58)
从 -1 开始
lr_scheduler
恢复旧状态
全新
EMA 状态
恢复
全新
load_tuning_state() line 249-274 的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 def load_tuning_state(self, path): # 1. 加载 checkpoint state = torch.load(path) pretrain_state_dict = state["ema"]["module"] # 2. 尝试调整 head 参数(处理 num_classes 不匹配) adjusted_state_dict = self._adjust_head_parameters( module.state_dict(), pretrain_state_dict ) # 3. 形状匹配的参数全部加载,不匹配的跳过 stat, infos = self._matched_state(module.state_dict(), adjusted_state_dict) module.load_state_dict(stat, strict=False)
关键:_adjust_head_parameters 只在 num_classes 不同时才调整/丢弃检测头。
注意按照机器核心调整num_workers,以便达到最佳性能。
开始训练
1 2 3 4 5 6 7 8 cd D-FINE python train.py -c ../config/volleyball_s_transfer.yml --use-amp --seed 0 -t weights/dfine_s_obj365.pth python train.py -c ../config/volleyball_s_transfer.yml --use-amp --seed 0 -r output/exp_s_transfer/last.pth + -c 接config配置文件路径 + -t 从预训练模型路径迁移tuning + -r 从last模型开始继续训练resume
分析和评估
分析
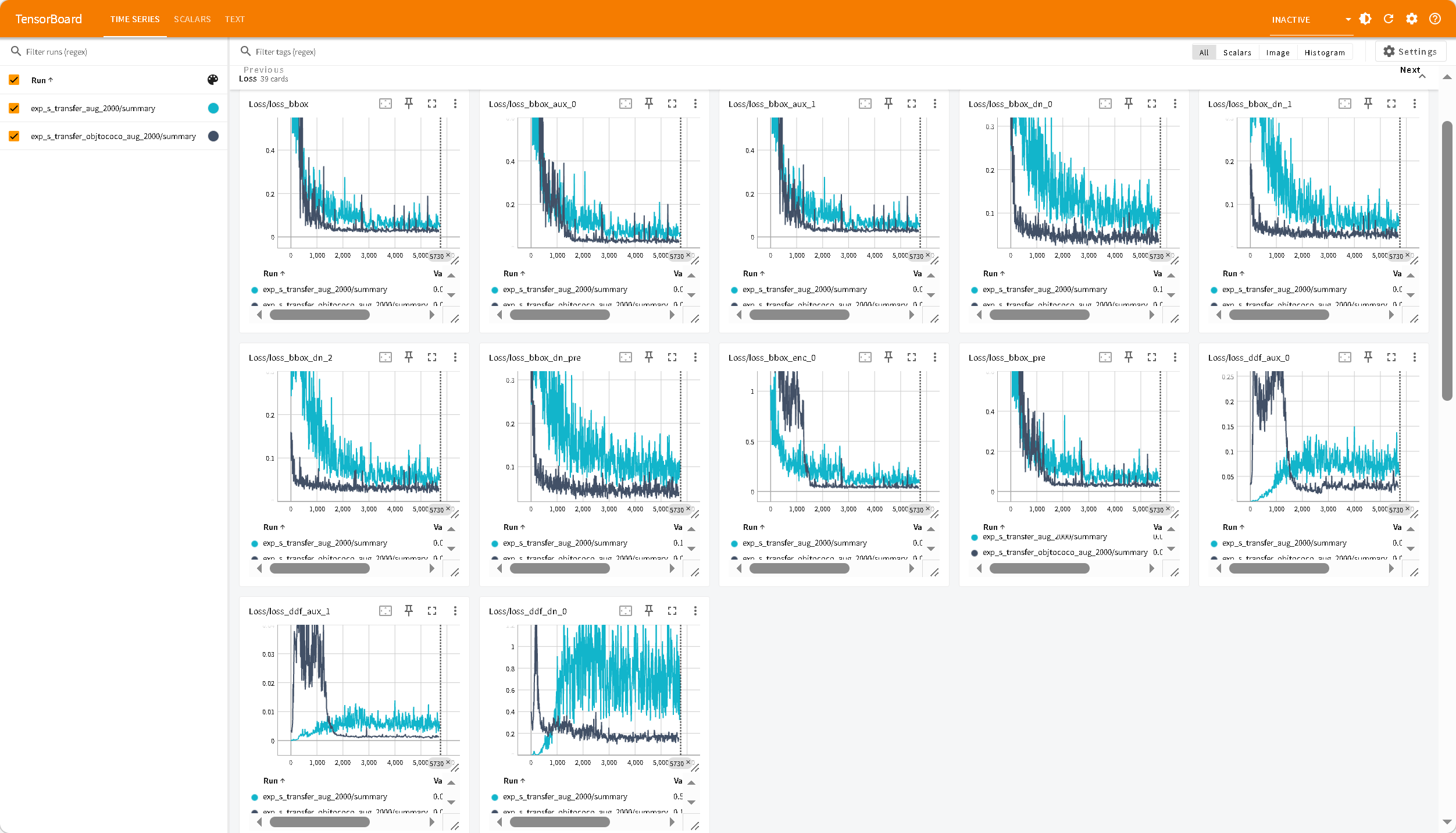
对于单目标排球训练,使用900张少量数据集迁移。
exp_s_transfer:obj365预训练模型迁移
exp_s_transfer_obj_aug:obj预训练模型+数据增强
exp_s_transfer_obj2coco_aug:obj2coco预训练模型+数据增强
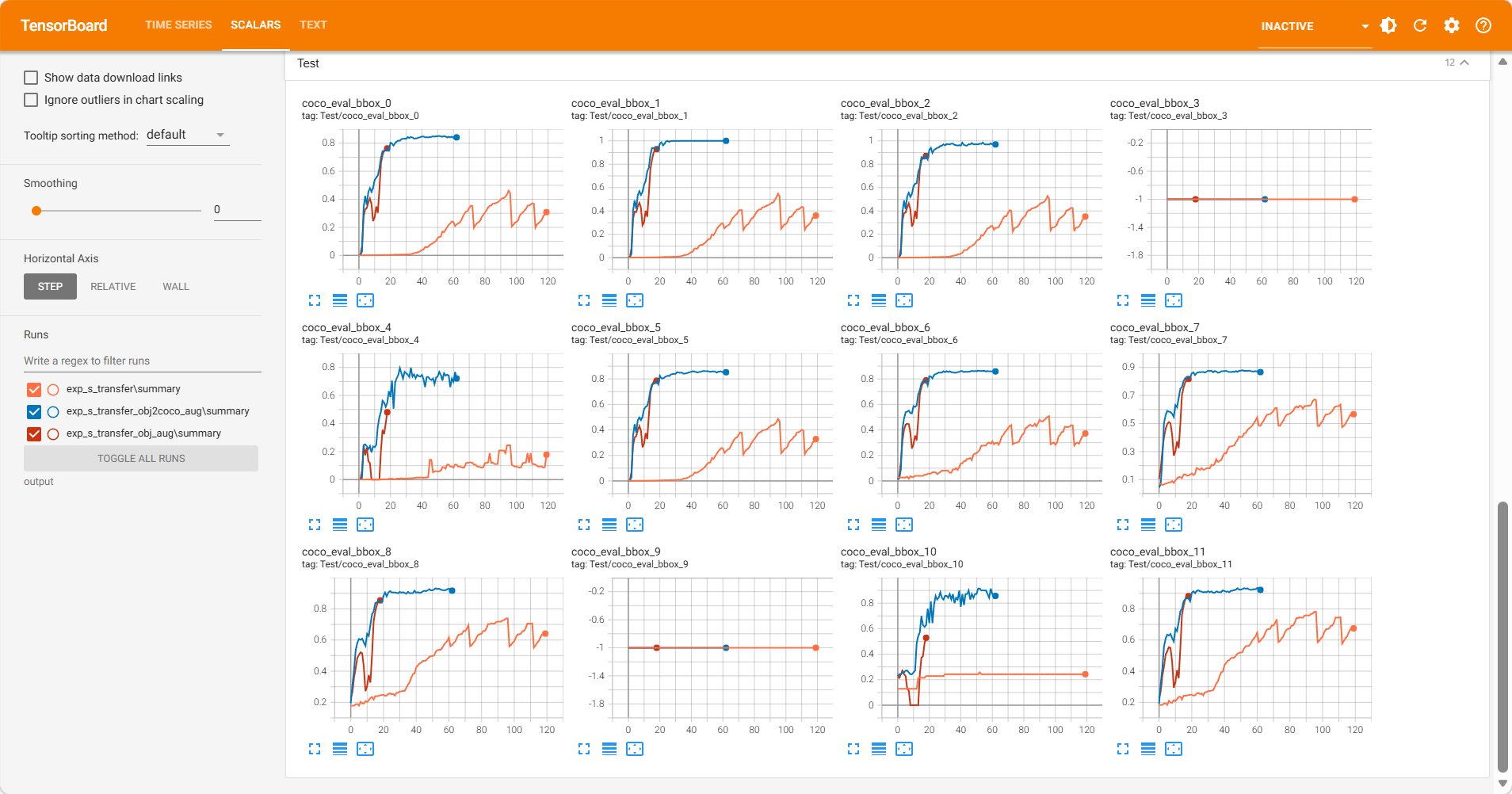
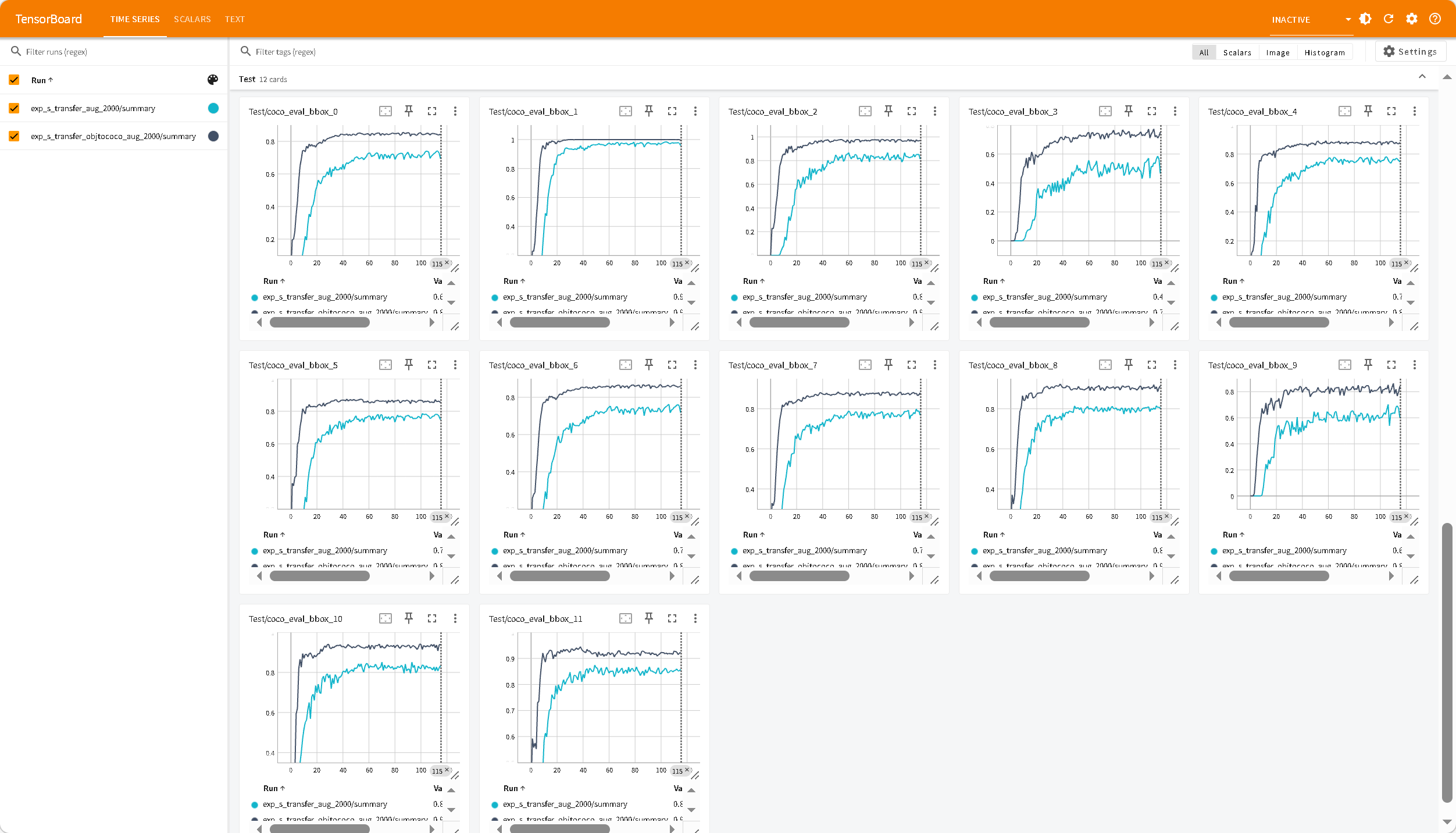
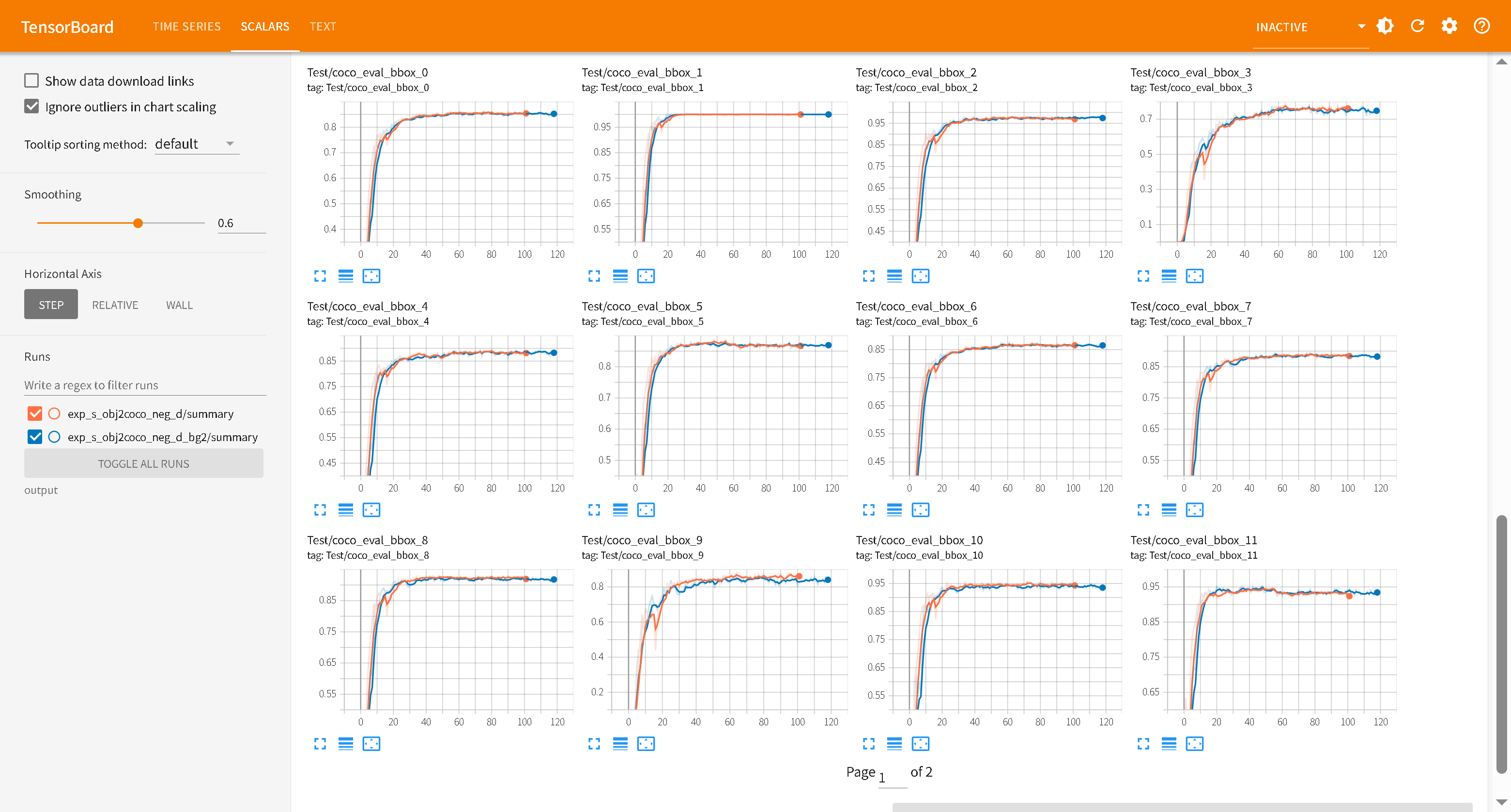
1 2 3 4 5 6 7 8 9 10 11 12 `Test/coco_eval_bbox_0`(Precision:AP50:95-all) `Test/coco_eval_bbox_1`(Precision:AP50) `Test/coco_eval_bbox_2`(Precision:AP70) `Test/coco_eval_bbox_3`(Precision:0.50:0.95-small) `Test/coco_eval_bbox_4`(Precision:0.50:0.95-medium) `Test/coco_eval_bbox_5`(Precision:0.50:0.95-large) `Test/coco_eval_bbox_6`(Recall:0.50:0.95-all-maxDets=1) `Test/coco_eval_bbox_7`(Recall:0.50:0.95-all-maxDets=10) `Test/coco_eval_bbox_8`(Recall:0.50:0.95-all-maxDets=100) `Test/coco_eval_bbox_9`(Recall:0.50:0.95-small-maxDets=100) `Test/coco_eval_bbox_10`(Recall:0.50:0.95-medium-maxDets=100) `Test/coco_eval_bbox_11`(Recall:0.50:0.95-large-maxDets=100)
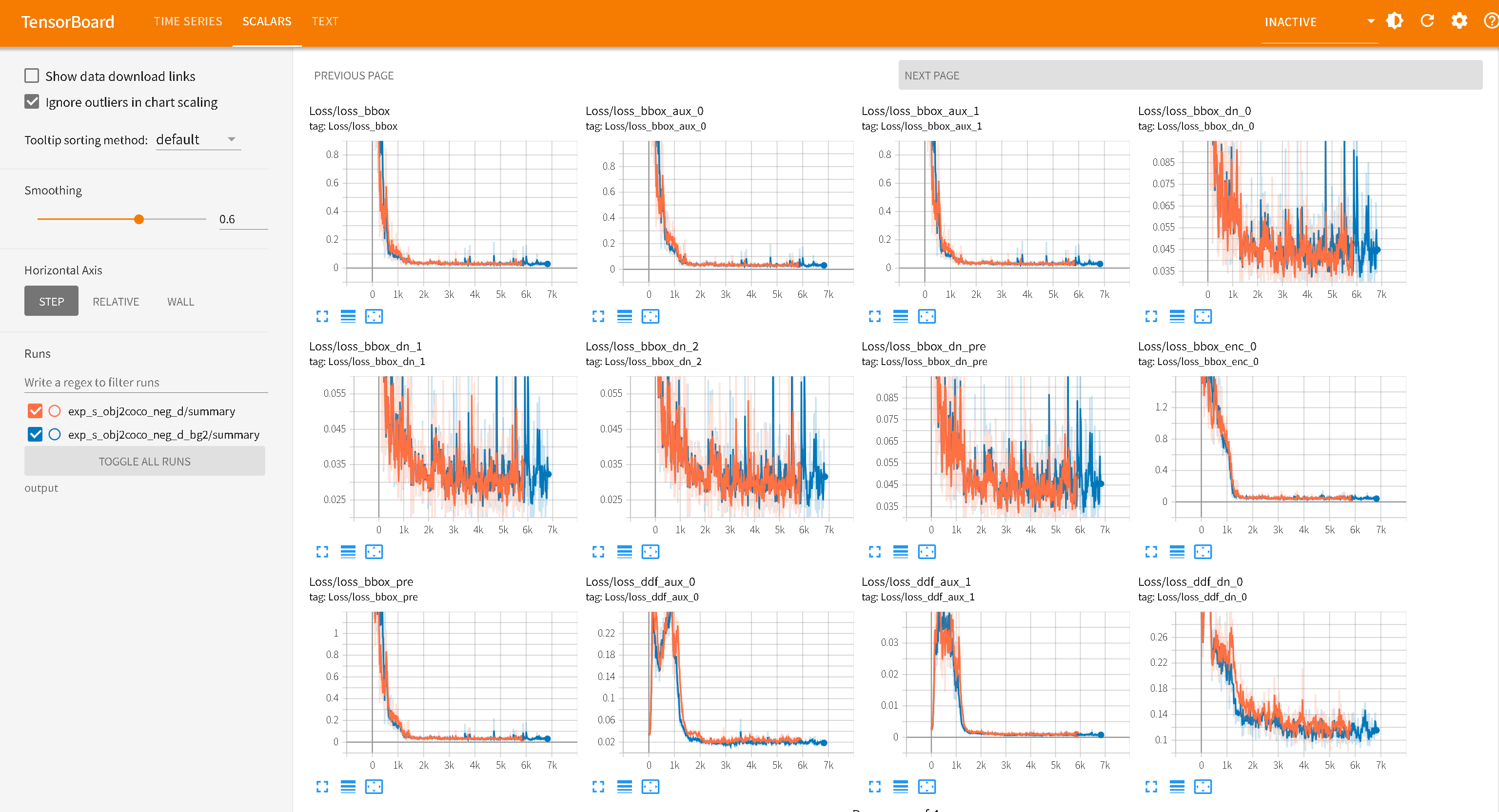
收敛:蓝色曲线的 AP(coco_eval_bbox_0)在大约 60 个 Epoch 前迅速上升,随后进入平台期
红色曲线 exp_s_transfer_obj_aug 前期训练loss抖动,而且AP/AR无法快速上升(后续没啥问题,都能用),疑似数据集过小问题,停止训练。obj 数据集里确实有“排球”这个类别(Class 240),但是COCO 的标注更为精准,且包含大量小目标。obj2coco数据集的质量和多样性更好。(官方说Objects365 预训练模型泛化性最好,其实差不多,感觉Objects365+COCO更好 )
无法收敛:橙黄色曲线 exp_s_transferobj365预训练模型,在训练了120Epoch后依旧无法收敛,表明900+数据集过小。
小目标缺失: coco_eval_bbox_3/9(代表 Small 尺寸的 AP/AR)。表示数据集中没有配置好小目标。
Loss 曲线在现代优化器(如 AdamW + Cosine Annealing)的加持下,通常都会表现良好,一般数据集没有问题,不会出现问题。主要查看AP/AR曲线即可。
数据集标注错误问题
标注数据集没有紧密贴合物体,模型无法正确收敛。
预训练模型迁移和从零开始对比
exp_s_transfer_objtococo_aug_2000为在obj2coco模型迁移微调,exp_s_transfer_aug_2000为从零开始训练,收敛需要更长时间。
查询过激活
术语
含义
Query Over-Activation (查询过激活)DETR 系列中,预训练的 learned queries 在微调后仍保留对非目标物体的定位能力,导致错误激活
False Activation (假激活)D-FINE Issue #277 中使用的原词,指模型对非目标物体产生高置信度检测
Objectness-Classification Conflation 目标性与分类的混淆——单类分类头退化为"是否有物体"而非"是否是目标类别"
Class Collapse (类别坍缩)多类预训练模型微调为单类后,分类维度坍缩,丧失类别区分能力
DETR 系列架构(D-FINE / RT-DETR)
D-FINE 基于 RT-DETR 改进,属于 DETR(DEtection TRansformer)家族。核心架构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 输入图像 │ ▼ ┌──────────────┐ │ Backbone │ HGNet-v2 (特征提取) │ (Encoder) │ └──────┬───────┘ │ 多尺度特征图 ▼ ┌──────────────┐ │ Hybrid │ 高效混合编码器 │ Encoder │ (特征融合 + 自注意力) └──────┬───────┘ │ ▼ ┌──────────────────────────────────┐ │ Transformer Decoder │ │ │ │ 300 个 Learned Object Queries │ ◄── 问题根源 │ × │ │ Cross-Attention (查询 × 特征) │ │ × │ │ 6 层 Decoder Layer │ └──────────┬───────────────────────┘ │ ┌─────┴─────┐ ▼ ▼ ┌─────────┐ ┌──────────┐ │ 分类头 │ │ 回归头 │ │ scores │ │ boxes │ │ labels │ │ (x1,y1, │ │ │ │ x2,y2) │ └─────────┘ └──────────┘
D-FINE 使用 300 个可学习的查询向量 (query embeddings)
每个 query 在训练过程中"专攻"检测特定位置和类型的物体
在 COCO 预训练中,这 300 个 query 学会了定位 80 类物体(人、车、椅子、球…)
推理时,每个 query 通过 cross-attention 与图像特征交互,输出一个检测结果
D-FINE输出层(单类)
1 2 3 4 5 6 7 8 9 10 11 P(class_i | query_j) = softmax([logit_volleyball, logit_no_object]) 其中 softmax 只有两个类别: logit_volleyball → "是排球" logit_no_object → "没有目标" 对于非排球物体(如人): query 的 cross-attention 被物体特征强激活 logit_volleyball 被推高(因为query认为"这里有东西") logit_no_object 被压低 P(volleyball) ≈ 0.85 → 超过阈值,误检!
解决方法:
方案 A:空标注图片加入训练Issue #277 必须打 Issue #247 补丁防止死锁
方案 B:训练策略调整
参数
当前值
建议值
说明
预训练权重
Obj365+COCO
无 / 仅 Objects365 单类简单场景从头训更好
eos_coefficient0.1(默认)
0.3-0.5 增大 no-object 损失权重,抑制假激活
num_queries300
50-100 减少 query 数量,降低过激活概率
学习率
-
transformer 1e-4, backbone 1e-5
过高导致训练崩溃
auxiliary_loss-
True每层 decoder 都加监督,学会正确的目标数量
Issue #277
原理:利用 D-FINE 已有的 contrastive denoising 机制,在非目标区域注入负样本,强制 query 学会抑制。不需要额外数据,但需要修改 src/zoo/dfine/denoising.py。
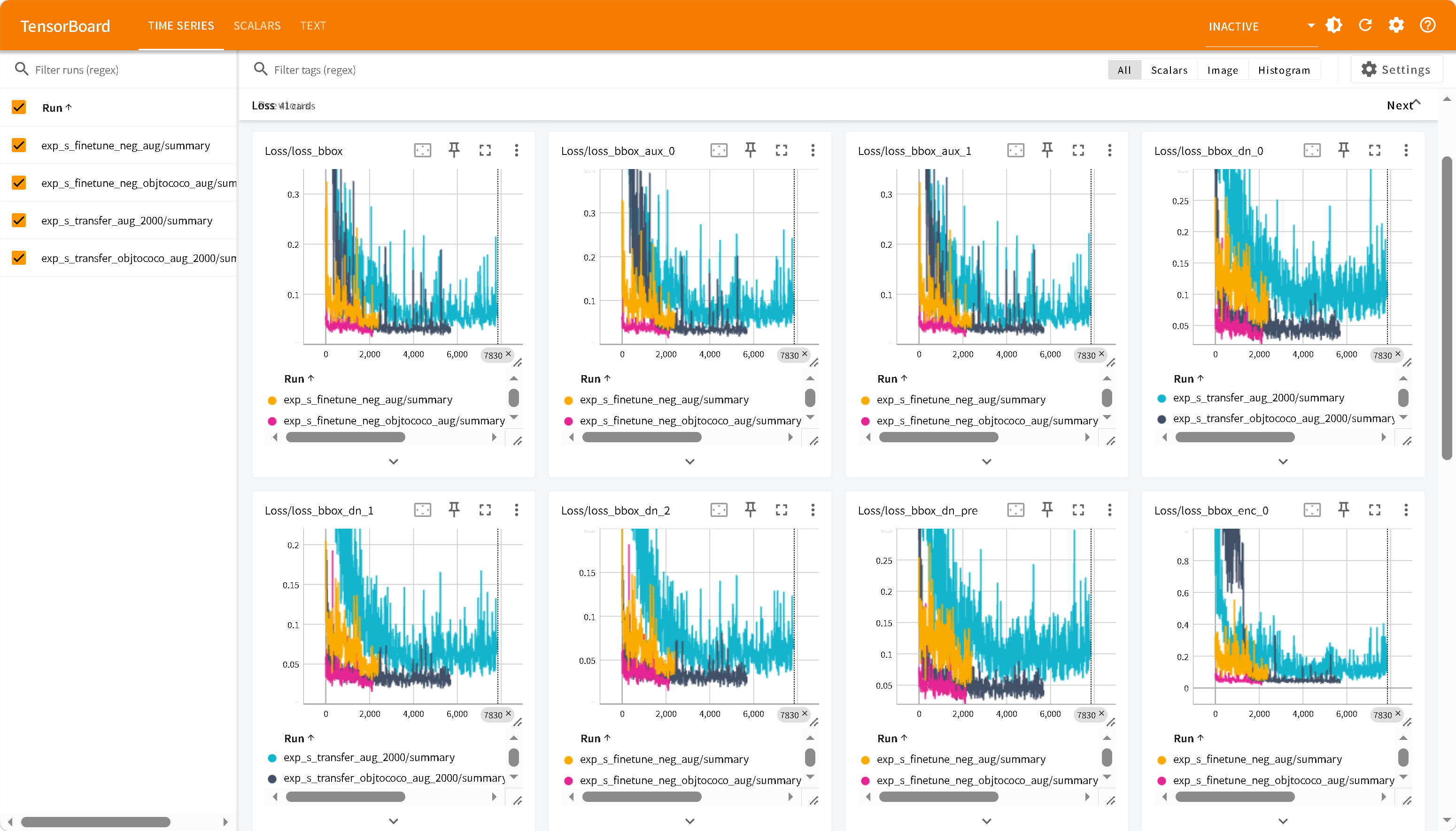
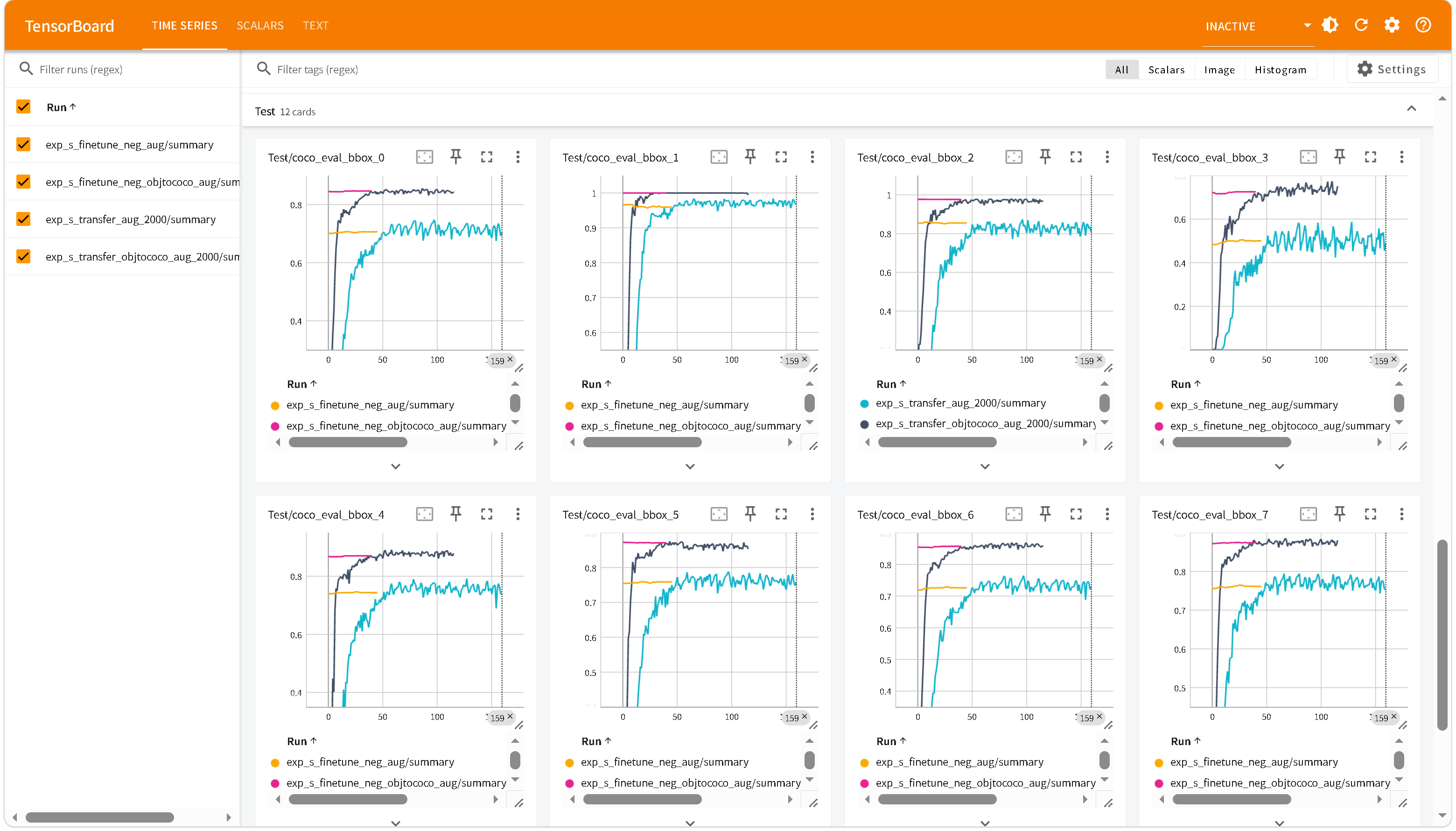
空标注微调
添加空标注图片样本作为负样本。
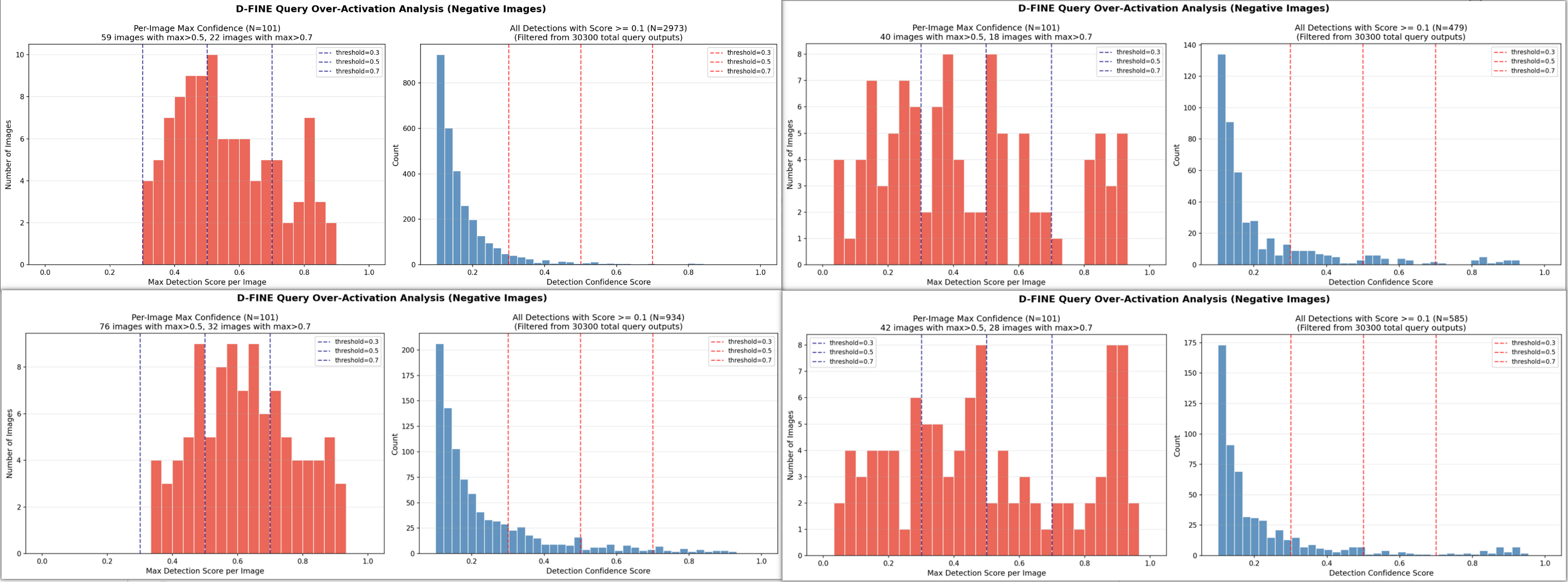
从左上,右上,左下,右下依次为:
exp_s_finetune_neg_aug exp_s_finetune_neg_objtococo_aug
exp_s_transfer_aug_2000 exp_s_transfer_objtococo_aug_2000
1 2 3 4 5 6 7 8 9 10 11 ┌────────────────────────────┬──────────┬────────────┬───────────┬───────────┬───────────┬────────┬────────────┐ │ 模型 │ 预训练 │ 负样本微调 │ FPPI @0.3 │ FPPI @0.5 │ FPPI @0.7 │ Max FP │ Clean @0.3 │ ├────────────────────────────┼──────────┼────────────┼───────────┼───────────┼───────────┼────────┼────────────┤ │ transfer_aug │ obj │ 否 │ 2.15 │ 0.83 │ 0.33 │ 0.930 │ 0% │ ├────────────────────────────┼──────────┼────────────┼───────────┼───────────┼───────────┼────────┼────────────┤ │ transfer_objtococo_aug │ obj+coco │ 否 │ 1.11 │ 0.48 │ 0.32 │ 0.938 │ 27.7% │ ├────────────────────────────┼──────────┼────────────┼───────────┼───────────┼───────────┼────────┼────────────┤ │ finetune_neg_aug │ obj │ 是 │ 2.36 │ 0.68 │ 0.22 │ 0.885 │ 0% │ ├────────────────────────────┼──────────┼────────────┼───────────┼───────────┼───────────┼────────┼────────────┤ │ finetune_neg_objtococo_aug │ obj+coco │ 是 │ 0.93 │ 0.45 │ 0.18 │ 0.925 │ 36.6% │ └────────────────────────────┴──────────┴────────────┴───────────┴───────────┴───────────┴────────┴────────────┘
FPPI @阈值(False Positives Per Image)
在置信度阈值下,平均每张背景图的误检数量
Max FP(最大误检置信度)
所有背景图中,最严重误检的置信度值
Clean @阈值(干净图片比例)
在置信度阈值下,完全没有任何误检的背景图占比
1 2 3 4 5 obj365 路线 obj2coco 路线 ────────── ───────────── 无负样本: 2.15 FPPI 1.11 FPPI ↓ 负样本微调 ↓ 负样本微调 有负样本: 2.36 FPPI (更差!) 0.93 FPPI (改善)
负样本微调有效,效果有限,原因是负样本只有101张,对于2000+数据集太少。
负样本微调让更多 query 的分数集中到 0.3-0.5区间,低置信度误检反而变多了,但高置信度误检减少了
DN随机负样本
在 denoising.py 中,在与图片原有目标没有交集的区域随机生成框,将其标签视为背景类参与分类损失
原理:利用 D-FINE 已有的 contrastive denoising 机制,在非目标区域注入负样本,强制 query 学会抑制。不需要额外数据,但需要修改 src/zoo/dfine/denoising.py。
参考51hhh/D-FINE_train at a285f6a7ab2cfa11bb381f0161289e0b4e83f876
每张图随机生成有限数量(如 50 个)的框
过滤掉与 GT 框重叠的(IoU > 0.3)
剩余框标记为 background 类(class_id = num_classes,即 padding index)
这些框只参与分类 loss (推向 no-object),不参与回归 loss
通过 DN 机制注入训练,无需额外数据
上图为exp_s_obj2coco_neg_d,下图为exp_s_obj2coco_neg_d_q100
1 2 3 4 5 6 7 8 9 10 11 ┌───────────────────┬──────────┬──────────┬────────────────┬──────────┬──────────┬────────────────┐ │ 模型 │ 策略 │ [email protected] │ Clean [email protected] │ Max Conf │ [email protected] │ Clean [email protected] │ ├───────────────────┼──────────┼──────────┼────────────────┼──────────┼──────────┼────────────────┤ │ obj2custom (基准) │ 无 │ 1.109 │ 27.7% │ 0.938 │ 0.475 │ 58.4% │ ├───────────────────┼──────────┼──────────┼────────────────┼──────────┼──────────┼────────────────┤ │ finetune_neg_aug │ 无D │ 0.931 │ 36.6% │ 0.925 │ 0.446 │ 60.4% │ ├───────────────────┼──────────┼──────────┼────────────────┼──────────┼──────────┼────────────────┤ │ neg_d │ A+D │ 0.040 │ 96.0% │ 0.417 │ 0.000 │ 100% │ ├───────────────────┼──────────┼──────────┼────────────────┼──────────┼──────────┼────────────────┤ │ neg_d_q100 │ A+D+Q100 │ 0.050 │ 96.0% │ 0.698 │ 0.010 │ 99.0% │ └───────────────────┴──────────┴──────────┴────────────────┴──────────┴──────────┴────────────────┘
neg_d 最优的:
添加bg_loss配置和训练中评估
exp_s_obj2coco_neg_d/对比exp_s_obj2coco_neg_d_bg2/
bg2添加了:
1 2 3 4 5 6 7 8 9 10 # ============ 背景 loss 权重(放大背景查询的 VFL loss 梯度)============ DFINECriterion: bg_loss_weight: 2.0 # ============ Over-Activation 训练中评估 ============ eval_overactivation: True negative_img_dir: "../coco/images/negative_samples" oa_conf_threshold: 0.3 oa_ap_tolerance: 0.005 # stg2 AP下降≤0.5%时,若OA改善则保存best_oa.pth跳过rollback
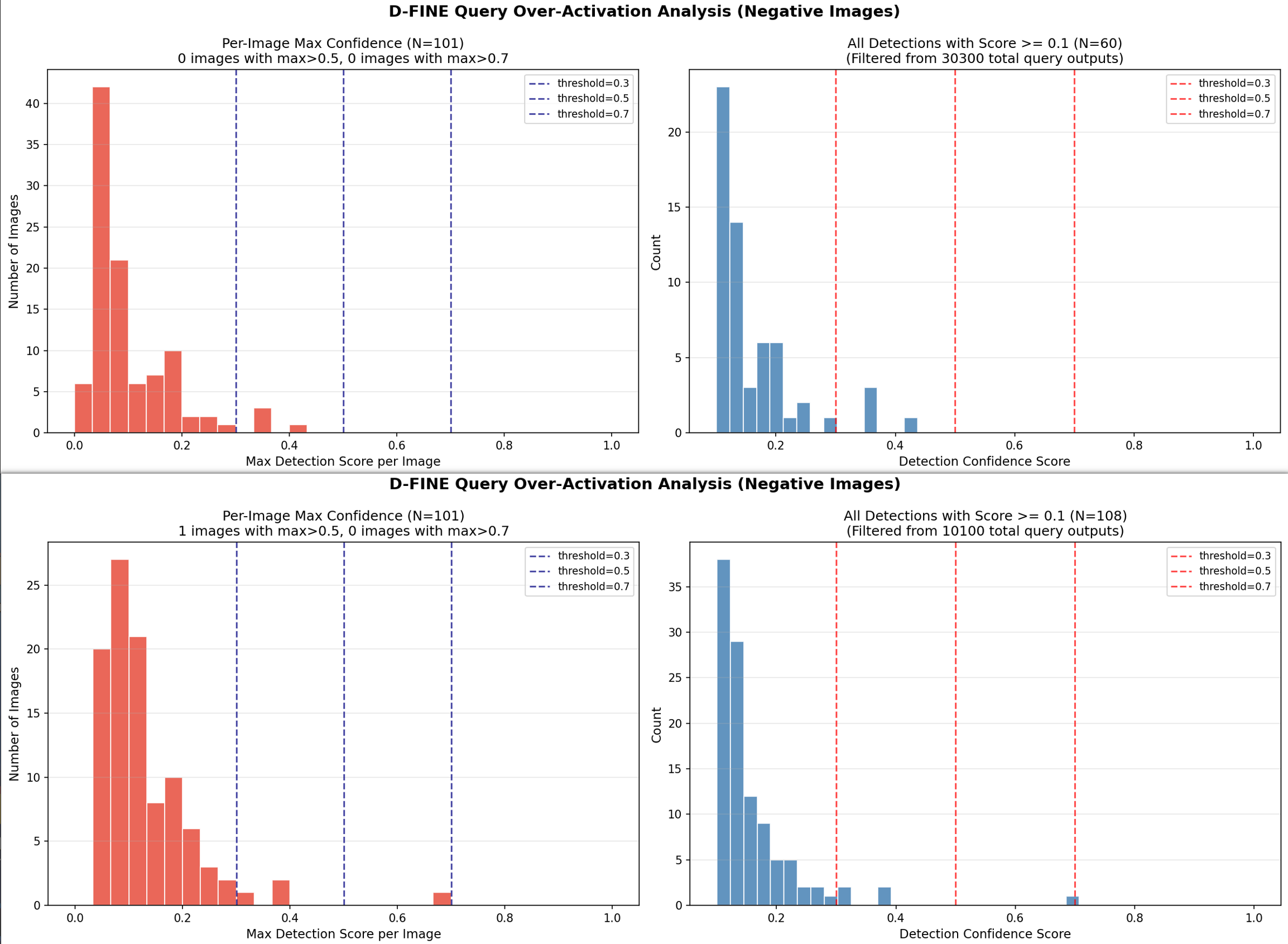
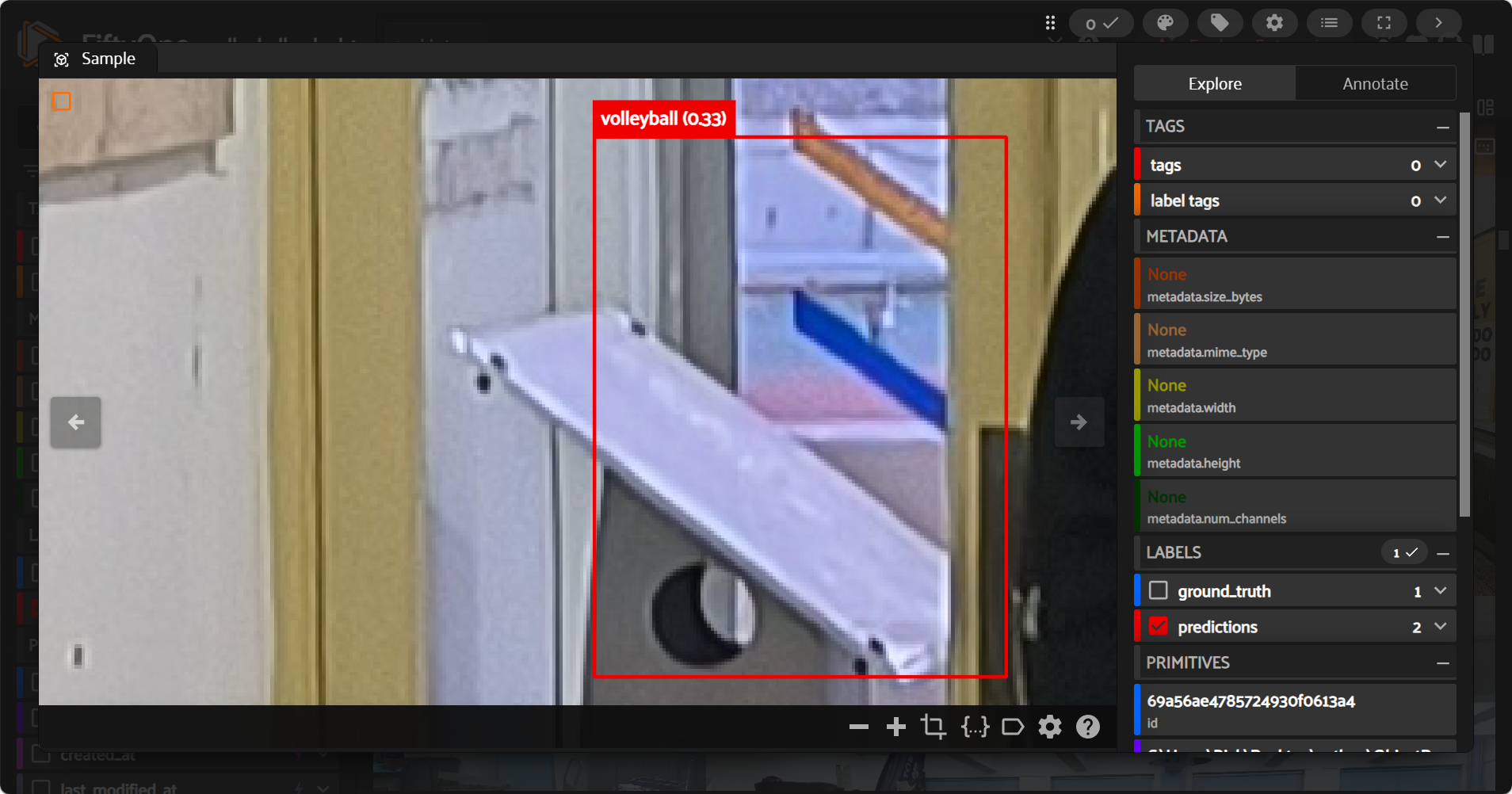
解决exp_s_obj2coco_neg_d实际部署依旧会存在误检测情况。(上图D-FINE Query Over-Activation Analysis (Negative Images)指标不对,训练exp_s_obj2coco_neg_d时候negative_samples已经存在训练集中,导致评估指标时候表现良好。)
!!!
注意negative_samples评估数据需要与训练中negative_samples不同,测评指标才具有参考价值。
Over-Activation 训练中评估开启后需要在test中对negative_samples数据集检验测评,因为oa保存best模型原因与训练不能并行,会导致每次epoch增加10s(具体取决于negative_samples大小和算力大小)
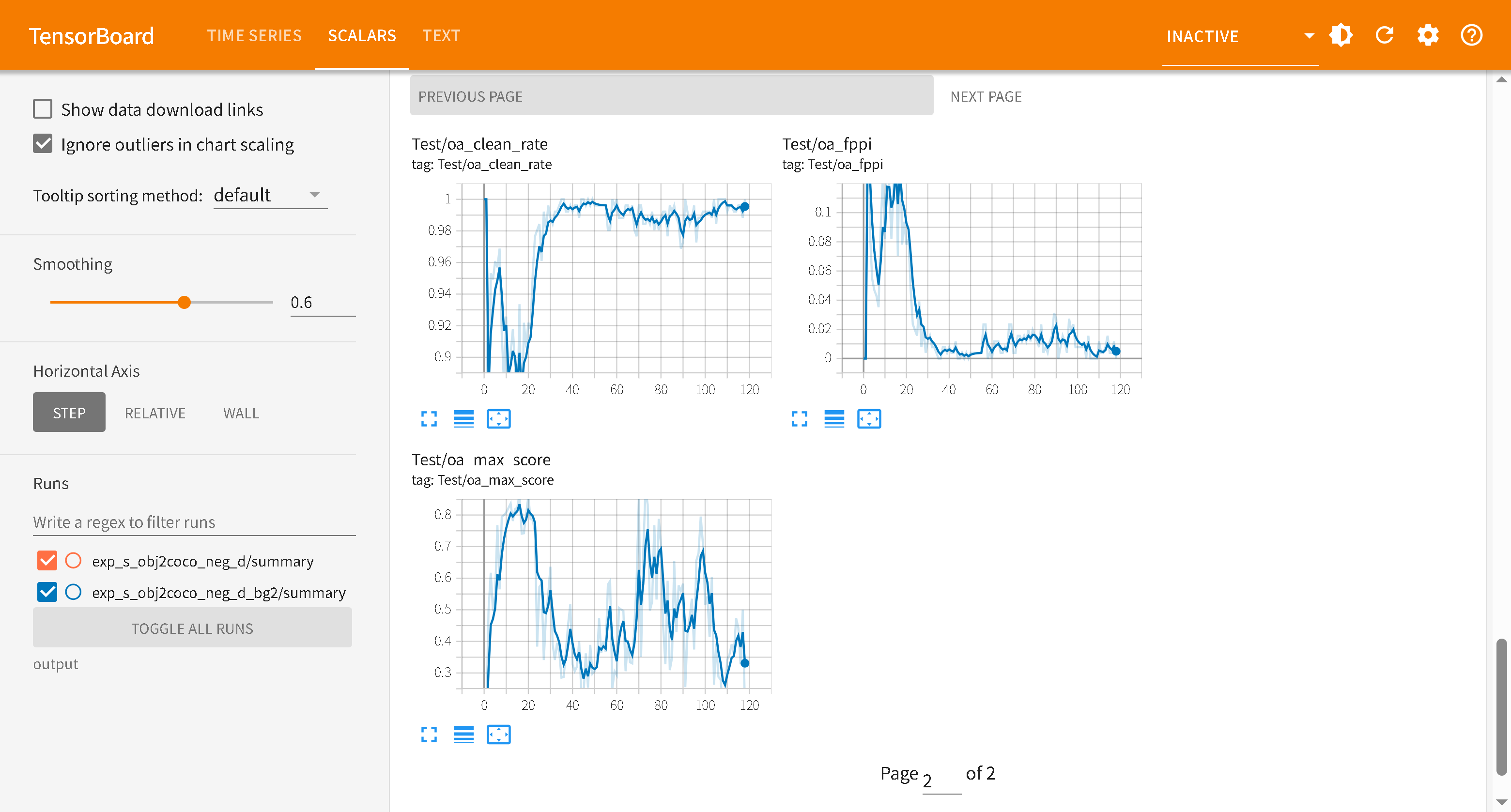
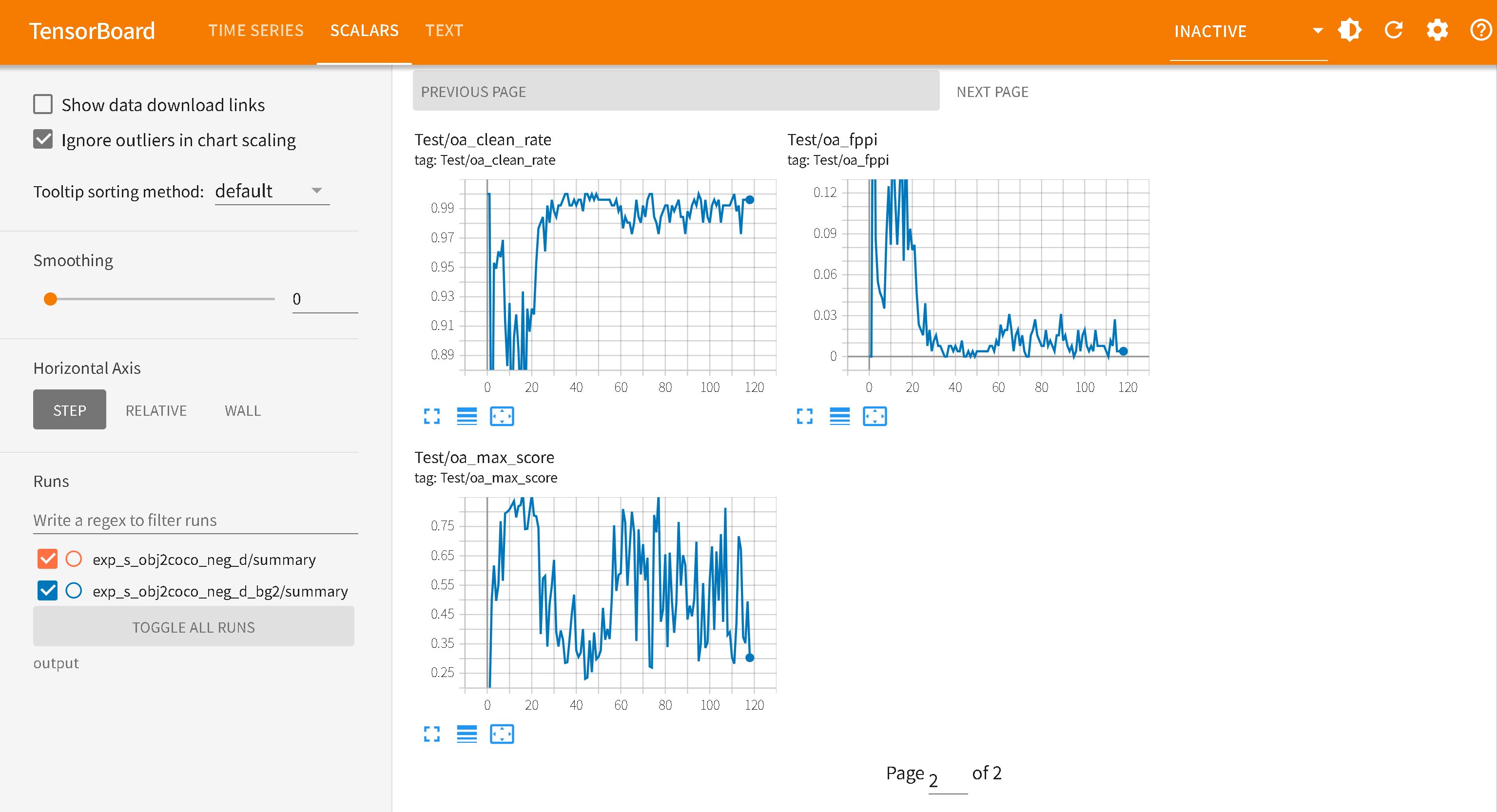
Test/oa_fppi — False Positives Per Image
每张负样本图的平均误检数 (置信度 >= oa_conf_threshold)
值
含义
0.04
100 张背景图共 4 个误检,几乎无误检(生产级)
2.15
100 张背景图共 215 个误检,严重过激活
值域:0 → ∞
理想值:< 0.05
趋势期望:随训练持续下降
Test/oa_clean_rate — Clean Image Rate
完全无误检的负样本图片比例
值
含义
0.96
100 张中 96 张完全干净,4 张有误检
0.00
所有图片都有至少一个误检(最差情况)
值域:0.0 → 1.0
理想值:> 0.95
趋势期望:随训练持续上升
Test/oa_max_score — Max Detection Score
所有负样本图中最高的单个误检置信度
值
含义
0.417
最严重误检置信度 41.7%,用 0.5 阈值可完全过滤(安全)
0.930
最严重误检置信度 93%,模型对误检极度自信(危险)
值域:0.0 → 1.0
理想值:< 0.5
趋势期望:随训练持续下降
边界框质量
D-FINE 将边界框回归重新定义为概率分布的精细化过程,而非直接回归坐标:
传统 DETR:query → [x, y, w, h](4个确定值)
这使得 D-FINE 的边界框质量更高
评估
主要查看COCO 评估指标能够准确判断模型情况。
D-FINE默认提供了模型在不同 IoU 阈值 和 目标尺寸 下的精度(Precision)和召回率(Recall)等参数。
IoU (Intersection over Union): 预测框与真实框的重叠度AP (Average Precision): 精确率曲线下的面积。AR (Average Recall): 召回率,即模型找全目标的能力。
术语 全称 含义 预测情况
TP True Positive 真正例 模型说是正类,实际也是 正类
TN True Negative 真负例 模型说是负类,实际也是 负类
FP False Positive 假正例 模型说是正类,实际却是 负类
FN False Negative 假负例 模型说是负类,实际却是 正类
精确率 (Precision)
定义: 在模型所有预测为正类 的样本中,真正是对的占比
$$Precision = \frac{TP}{TP + FP}$$
高精确率 (High Precision)表示模型检测到10个目标,有9个是正确的,检测精准正确。可能在很有把握才识别,容易漏识别,即低Recall
召回率 (Recall)
定义: 在所有实际为正类 的样本中,模型成功找出的占比
$$Recall = \frac{TP}{TP + FN}$$
高召回率 (High Recall)表示模型在10个真正目标中,检测到9个,很少漏检,可能过于自信,检测到假目标,即低Precision
精确率和召回率往往是此消彼长 的(Trade-off),可以使用F1-Score 来平衡这两者
主要查看指标
AP @[ IoU=0.50:0.95 ]
mAP @[ IoU=0.50:0.95 ]
AP @[ IoU=50/75]IoU > 0.5 ,就认为它是 TP,较为宽容,而75则更为严格,要求模型的预测框必须与真实框高度重合 。
area=small/medium/large
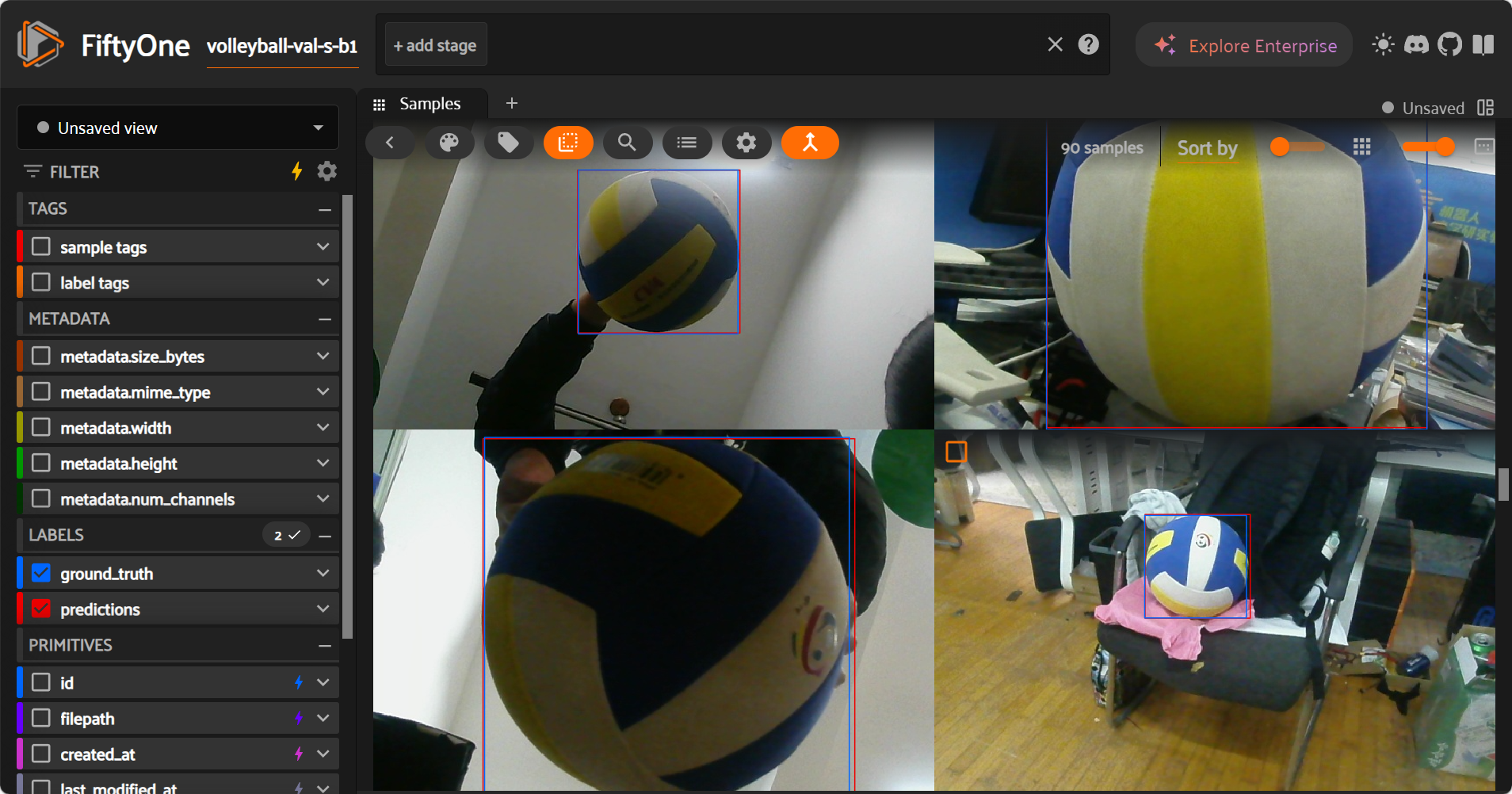
可视化
使用 fiftyone可视化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 import json import sys from collections import defaultdict from pathlib import Path import fiftyone as fo import fiftyone.core.labels as fol import torch import torchvision.transforms as T from PIL import Image from tqdm import tqdm # ========================== # Hardcoded runtime settings # ========================== # 修改这里即可,无需命令行传参 SETTINGS = { "repo_dir": "./D-FINE", "config": "./config/volleyball_s_transfer.yml", "checkpoint": "./D-FINE/output/exp_s_transfer_obj2coco_aug/best_stg1.pth", # 最新的最佳权重 "img_root": "./coco/images", "ann_file": "./coco/converted/annotations/val.json", "dataset_name": "volleyball-val-s-b1", "eval_key": "eval", "device": "cuda:0", "input_size": 640, "conf_thres": 0.25, "limit": 0, # 0 = all "overwrite": True, "no_app": False, } def load_dfine_model(repo_dir: Path, config_path: str, checkpoint_path: str, device: str): sys.path.insert(0, str(repo_dir.resolve())) from src.core import YAMLConfig safe_config_path = prepare_windows_readable_config(Path(config_path)) try: cfg = YAMLConfig(str(safe_config_path), resume=checkpoint_path) finally: cleanup_temp_config(safe_config_path, Path(config_path)) if "HGNetv2" in cfg.yaml_cfg: cfg.yaml_cfg["HGNetv2"]["pretrained"] = False try: checkpoint = torch.load(checkpoint_path, map_location="cpu", weights_only=True) except TypeError: checkpoint = torch.load(checkpoint_path, map_location="cpu") except Exception: checkpoint = torch.load(checkpoint_path, map_location="cpu") state = checkpoint["ema"]["module"] if "ema" in checkpoint else checkpoint["model"] cfg.model.load_state_dict(state, strict=False) model = cfg.model.deploy().to(device).eval() postprocessor = cfg.postprocessor.deploy().to(device).eval() return model, postprocessor def prepare_windows_readable_config(config_path: Path) -> Path: """ D-FINE's yaml loader opens files without explicit encoding. On Windows this can default to GBK and fail on UTF-8 comments. This helper creates a GBK-readable temporary copy in the same directory. """ if not config_path.exists(): raise FileNotFoundError(f"Config file not found: {config_path}") text = None for enc in ("utf-8-sig", "utf-8", "gbk"): try: text = config_path.read_text(encoding=enc) break except UnicodeDecodeError: continue if text is None: raise RuntimeError(f"Cannot decode config file: {config_path}") # Build an ASCII-only temporary config so both UTF-8 and GBK default decoders can read it. safe_text = text.encode("ascii", errors="ignore").decode("ascii") tmp_path = config_path.parent / f".fo_tmp_{config_path.stem}.yml" tmp_path.write_text(safe_text, encoding="utf-8") return tmp_path def cleanup_temp_config(tmp_path: Path, original_config_path: Path): # Do not remove if it's exactly the original file path if tmp_path.resolve() == original_config_path.resolve(): return try: if tmp_path.exists(): tmp_path.unlink() except Exception: pass def load_coco(ann_file: Path): data = json.loads(ann_file.read_text(encoding="utf-8")) images = data["images"] annotations = data["annotations"] categories = data["categories"] anns_by_image = defaultdict(list) for ann in annotations: anns_by_image[ann["image_id"]].append(ann) cat_id_to_name = {c["id"]: c["name"] for c in categories} return images, anns_by_image, cat_id_to_name def clamp01(x): return max(0.0, min(1.0, x)) def coco_bbox_to_fo_detection(bbox_xywh, w, h, label, confidence=None): x, y, bw, bh = bbox_xywh nx = clamp01(x / w) ny = clamp01(y / h) nw = clamp01(bw / w) nh = clamp01(bh / h) kwargs = dict(label=label, bounding_box=[nx, ny, nw, nh]) if confidence is not None: kwargs["confidence"] = float(confidence) return fol.Detection(**kwargs) def xyxy_abs_to_fo_detection(box_xyxy, w, h, label, confidence): x1, y1, x2, y2 = box_xyxy x1 = clamp01(float(x1) / w) y1 = clamp01(float(y1) / h) x2 = clamp01(float(x2) / w) y2 = clamp01(float(y2) / h) bw = clamp01(x2 - x1) bh = clamp01(y2 - y1) return fol.Detection( label=label, bounding_box=[x1, y1, bw, bh], confidence=float(confidence), ) def unpack_predictions(pred_output): """ Support both formats: 1) deploy mode tuple: (labels, boxes, scores), each shape [B, Q, ...] 2) training/eval mode list[dict]: [{'labels','boxes','scores'}, ...] Returns tensors for a single sample: labels_1d, boxes_2d, scores_1d """ # deploy tuple if isinstance(pred_output, (tuple, list)) and len(pred_output) == 3 and torch.is_tensor(pred_output[0]): labels_b, boxes_b, scores_b = pred_output return labels_b[0], boxes_b[0], scores_b[0] # list of dicts if isinstance(pred_output, list) and len(pred_output) > 0 and isinstance(pred_output[0], dict): first = pred_output[0] return first["labels"], first["boxes"], first["scores"] raise TypeError(f"Unsupported prediction output type: {type(pred_output)}") @torch.no_grad() def run(): cfg = SETTINGS repo_dir = Path(cfg["repo_dir"]) img_root = Path(cfg["img_root"]) ann_file = Path(cfg["ann_file"]) if fo.dataset_exists(cfg["dataset_name"]): if cfg["overwrite"]: fo.delete_dataset(cfg["dataset_name"]) else: raise RuntimeError( f"Dataset '{cfg['dataset_name']}' already exists. Set SETTINGS['overwrite']=True to replace it." ) images, anns_by_image, cat_id_to_name = load_coco(ann_file) if cfg["limit"] and cfg["limit"] > 0: images = images[: cfg["limit"]] model, postprocessor = load_dfine_model( repo_dir, cfg["config"], cfg["checkpoint"], cfg["device"] ) tfm = T.Compose( [ T.Resize((cfg["input_size"], cfg["input_size"])), T.ToTensor(), ] ) dataset = fo.Dataset(cfg["dataset_name"]) for img_info in tqdm(images, desc="Building FiftyOne dataset"): image_id = img_info["id"] file_name = img_info["file_name"] width = img_info["width"] height = img_info["height"] image_path = img_root / file_name if not image_path.exists(): # Skip missing files instead of hard failing continue sample = fo.Sample(filepath=str(image_path.resolve())) # Ground truth gt_dets = [] for ann in anns_by_image.get(image_id, []): cat_id = ann["category_id"] label = cat_id_to_name.get(cat_id, str(cat_id)) gt_dets.append(coco_bbox_to_fo_detection(ann["bbox"], width, height, label)) sample["ground_truth"] = fol.Detections(detections=gt_dets) # Prediction image = Image.open(image_path).convert("RGB") tensor = tfm(image).unsqueeze(0).to(cfg["device"]) orig_target_sizes = torch.tensor( [[width, height]], dtype=torch.float32, device=cfg["device"] ) outputs = model(tensor) pred_output = postprocessor(outputs, orig_target_sizes) labels_t, boxes_t, scores_t = unpack_predictions(pred_output) labels = labels_t.detach().cpu().tolist() boxes = boxes_t.detach().cpu().tolist() scores = scores_t.detach().cpu().tolist() pred_dets = [] for label_id, box, score in zip(labels, boxes, scores): if score < cfg["conf_thres"]: continue # Handle both 0-based and 1-based label id conventions if label_id in cat_id_to_name: label_name = cat_id_to_name[label_id] elif (label_id + 1) in cat_id_to_name: label_name = cat_id_to_name[label_id + 1] else: label_name = str(label_id) pred_dets.append(xyxy_abs_to_fo_detection(box, width, height, label_name, score)) sample["predictions"] = fol.Detections(detections=pred_dets) dataset.add_sample(sample) results = dataset.evaluate_detections( "predictions", gt_field="ground_truth", eval_key=cfg["eval_key"], compute_mAP=True, ) try: print(f"mAP: {results.mAP():.6f}") except Exception: print("mAP: unavailable") print(f"Dataset: {dataset.name}") print(f"Samples: {len(dataset)}") print("Use FiftyOne sidebar to inspect FP/FN and per-sample errors.") if not cfg["no_app"]: session = fo.launch_app(dataset) session.wait() if __name__ == "__main__": run()
手工标注的数据集与实际目标边缘存在较大误差,实测模型识别得更为精准。可以更新数据集,再次训练使得AP继续上升。
可以将图片添加为负样本继续微调。
负样本微调
咕咕咕。。。
部署
咕咕咕。。。

 wechat
wechat Alipay
Alipay


